


前言
因为从
1.29.2之后的版本开始不支持jdk1.8因为还在使用jdk1.8的请下载1.29.2版本,否则请下载最新版本。

基本安装配置
wget https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
tar -zxvf maxwell-1.29.2.tar.gz
cd maxwell-1.29.2
mysql开启binlog日志
vi /etc/my.cnf
--------增加下面的配置----------------
......
log-bin=mysql-bin # binlog日志文件的前缀
binlog-format=row
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db = mysql
expire_logs_days=7
......
修改完重启mysql即可
mysql增量同步
启动maxwell并连接到指定数据库
启动成功如下,并会在所连接的数据库中创建一个名字为
maxwell的数据库,以及一些基本的表,用于存放同步信息后面会用到记一下。
[root@iZuf6ewt8qjkzg2vczg0uyZ maxwell-1.29.2]# bin/maxwell --user='root' --password='xxxxxxxxxxx' --host='101.132.x.x' --producer=stdout
Using kafka version: 1.0.0
22:22:16,479 INFO Maxwell - Starting Maxwell. maxMemory: 435879936 bufferMemoryUsage: 0.25
22:22:16,574 INFO SchemaStoreSchema - Creating maxwell database
22:22:16,955 INFO Maxwell - Maxwell v1.29.2 is booting (StdoutProducer), starting at Position[BinlogPosition[mysql-bin.000004:4569], lastHeartbeat=0]
22:22:17,225 INFO AbstractSchemaStore - Maxwell is capturing initial schema
22:22:18,499 INFO BinlogConnectorReplicator - Setting initial binlog pos to: mysql-bin.000004:4569
22:22:18,543 INFO BinaryLogClient - Connected to 101.132.x.x:3306 at mysql-bin.000004/4569 (sid:6379, cid:17)
22:22:18,543 INFO BinlogConnectorReplicator - Binlog connected.
手动修改或者增加删除数据库数据看上面控制台输出
22:27:01,755 INFO AbstractSchemaStore - storing schema @Position[BinlogPosition[mysql-bin.000004:114750], lastHeartbeat=1638973620647] after applying "CREATE DATABASE `test001` CHARACTER SET 'utf8mb4'" to test001, new schema id is 2
22:27:36,294 INFO AbstractSchemaStore - storing schema @Position[BinlogPosition[mysql-bin.000004:118427], lastHeartbeat=1638973652772] a )" to test001, new schema id is 301`.`sys_user` (
{"database":"test001","table":"sys_user","type":"insert","ts":1638973671,"xid":1326,"commit":true,"data":{"id":1,"username":"suke","password":"123456"}}
{"database":"test001","table":"sys_user","type":"insert","ts":1638973687,"xid":1374,"commit":true,"data":{"id":2,"username":"suke001","password":"123456"}}
{"database":"test001","table":"sys_user","type":"insert","ts":1638973701,"xid":1418,"commit":true,"data":{"id":3,"username":"suke002","password":"123456"}}
{"database":"test001","table":"sys_user","type":"delete","ts":1638973706,"xid":1437,"commit":true,"data":{"id":3,"username":"suke002","password":"123456"}}
{"database":"test001","table":"sys_user","type":"update","ts":1638973710,"xid":1457,"commit":true,"data":{"id":2,"username":"suke011","password":"123456"},"old":{"username":"suke001"}}
以上就是从创建库到创建表,再到增加数据,删除数据,修改数据的maxwell控制台同步输出,输出类型为json,增删改查语句的基本差别就是type字段里面的区分,很容易识别
启动成功后会在所创建的库和表

mysql全量同步
maxwell元数据库中找到bootstrap表,增加自己要全量同步的表信息
bootstrap表结构,不用你创建,人家自带的,里面有你要同步的库字段,表字段,is_complete字段0代表未开始,1代表同步完成。
CREATE TABLE `bootstrap` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`database_name` varchar(255) CHARACTER SET utf8 NOT NULL,
`table_name` varchar(255) CHARACTER SET utf8 NOT NULL,
`where_clause` text COLLATE utf8_unicode_ci,
`is_complete` tinyint(1) unsigned NOT NULL DEFAULT '0',
`inserted_rows` bigint(20) unsigned NOT NULL DEFAULT '0',
`total_rows` bigint(20) unsigned NOT NULL DEFAULT '0',
`created_at` datetime DEFAULT NULL,
`started_at` datetime DEFAULT NULL,
`completed_at` datetime DEFAULT NULL,
`binlog_file` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`binlog_position` int(10) unsigned DEFAULT '0',
`client_id` varchar(255) CHARACTER SET latin1 NOT NULL DEFAULT 'maxwell',
`comment` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
执行以下sql,相当于创建同步任务
INSERT bootstrap (`database_name`,table_name) VALUES ('test001','sys_user')
表里准备基础数据如下
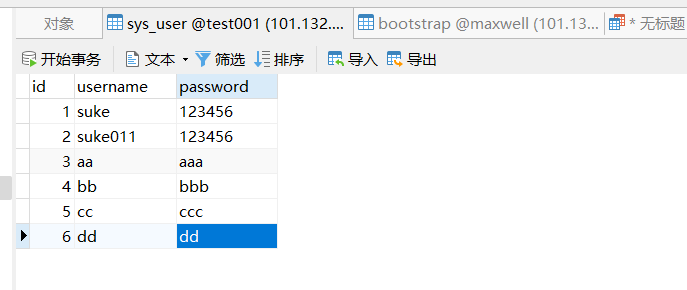
启动maxwell开始同步
bin/maxwell --user='root' --password='xxxxxxxxxx' --host='101.132.x.x' --producer=stdout
- 同步过程图
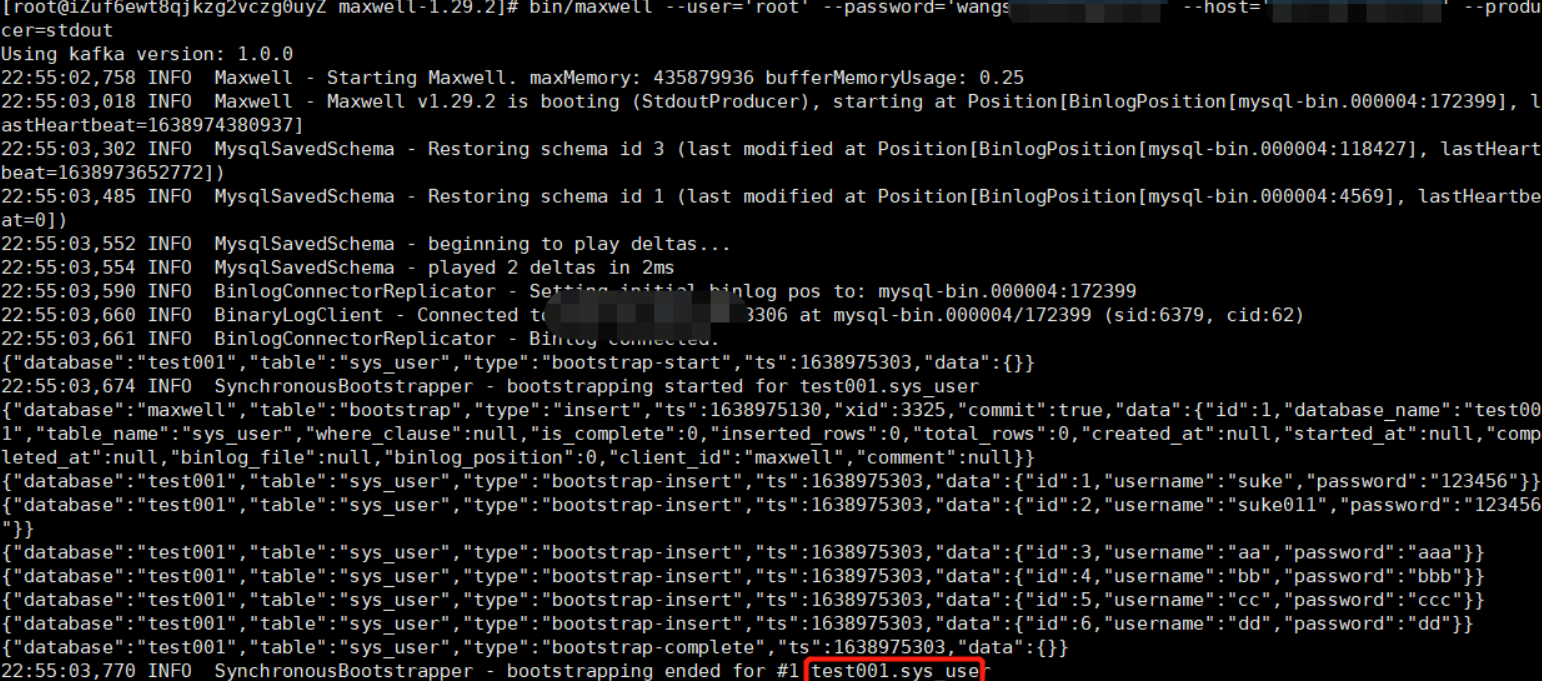
- 同步完成后
bootstrap插入的数据变化

概述
因为是基于
binlog的,因此可以把他当作mysql主从复制中的从库,在这个模式中,拿到数据库的基本日志信息,再处理成标准且固定格式json,发送到不通的客户端(接收者),正如配置中的描述

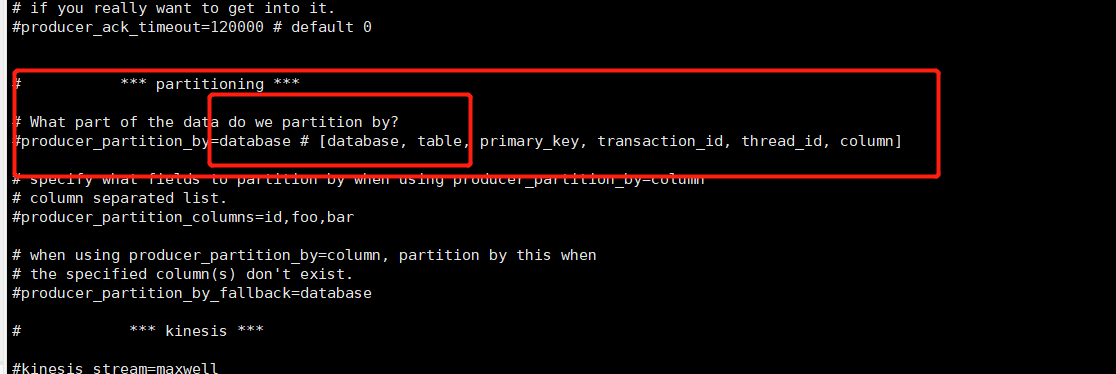
我们生产环境中最常见的就是利用
kafka,利用maxwell,可以很轻易的将数据发送到kafka的不通topic,甚至可以根据不同的数据库或者表分发到不同的topic的分区中,很大程度上帮我们处理了数据同步中的各种问题.kafka分发到不同分区配置截图如下:
评论区